爬虫扫盲练习。
实战练习:豆瓣电影 TOP250
源码:
1 | import requests |
实现步骤
安装
Requests和BeautifulSoup库。1
2pip install Requests
pip install BeautifulSoup导入
Requests库,并爬取豆瓣电影 TOP2501
2
3
4import requests
response = requests.get("https://movie.douban.com/top250")
print(response.status_code) #直接打印 response 或 response.status_code 都可以运行代码,返回 418,表示豆瓣不想理你。
加入请求头(headers)将代码伪装成浏览器。
浏览器打开豆瓣电影 Top 250 (douban.com),点击右键→选择【检查】→选择【网络】,在【名称】中找到【top250】,查看【标头】→【请求标头】→【User-Agent】,复制冒号后面的内容。
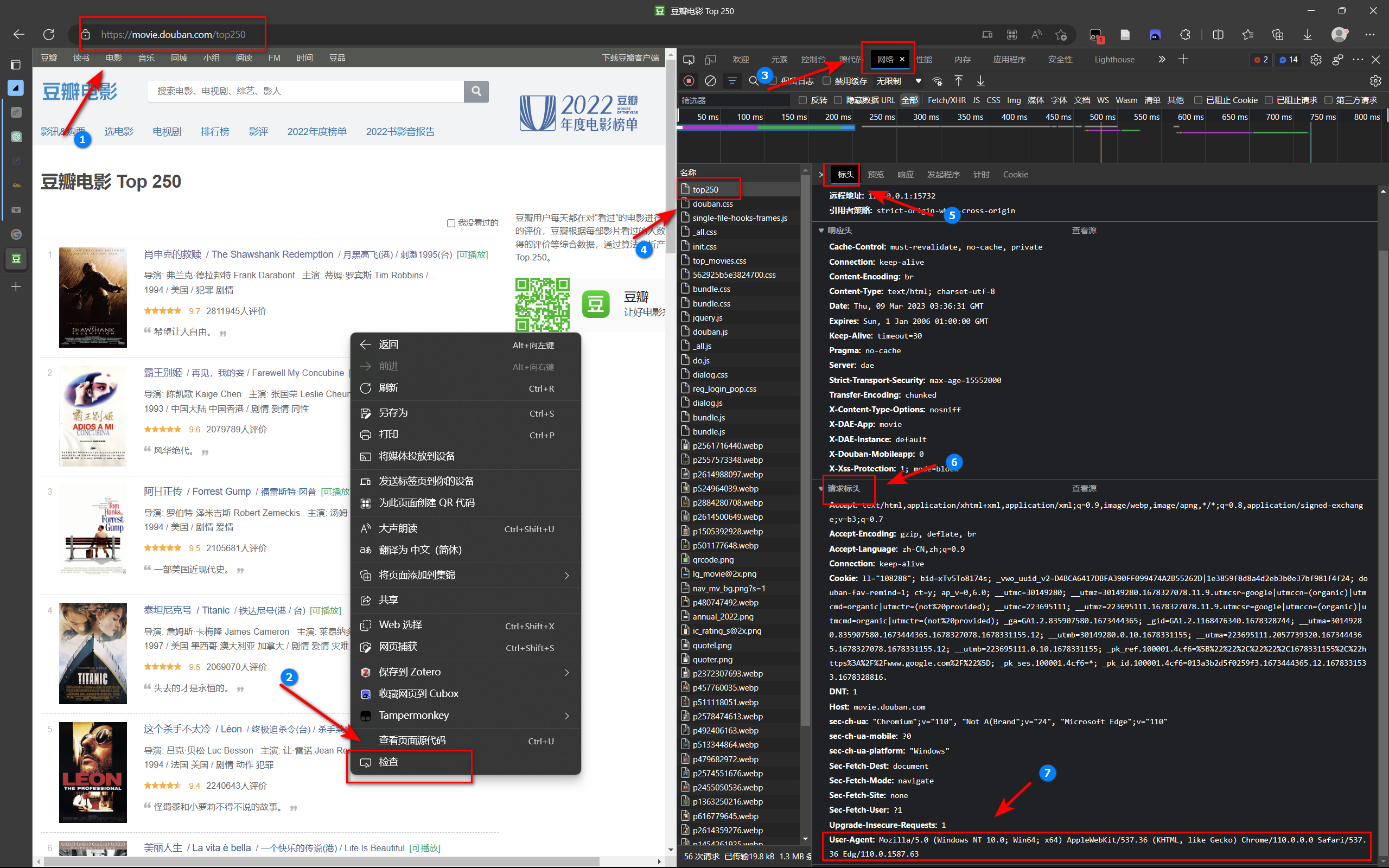
在代码中加入 headers。
1
2
3
4
5
6
7
8
9import requests
header = {
"User-Agent": "Mozilla/5.0 (Linux; Android 6.0; Nexus 5 Build/MRA58N) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/110.0.0.0 Mobile Safari/537.36 Edg/110.0.1587.63"
}
response = requests.get("https://movie.douban.com/top250", headers=header)
print(response.status_code) #返回值 200,表示正常访问
print(response.text) #可以看到打印下来 HTML 代码可以把 reponse.text 的返回值命名为 html,使用 BeautifulSoup 去解析,返回值命名为 soup,然后调用 soup 的属性 findAll,返回值命名为 all_title。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34import requests
header = {
"User-Agent": "Mozilla/5.0 (Linux; Android 6.0; Nexus 5 Build/MRA58N) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/110.0.0.0 Mobile Safari/537.36 Edg/110.0.1587.63"
}
response = requests.get("https://movie.douban.com/top250", headers=header)
html = response.text
soup = BeautifulSoup(html, "html.parser")
all_titles = soup.findAll("span", attrs={"class": "title"})
for title in all_titles:
print(title)
---
#打印结果
<span class="title">疯狂动物城</span>
<span class="title"> / Zootopia</span>
---
#如果只想要文字元素,则改为
for title in all_titles:
print(title.string)
---
#打印结果
疯狂动物城
/ Zootopia
---
#这时候会有原名,分析发现原名前面都有 /,使用 if 语句判断,即可剔除掉
for title in all_titles:
title_string = title.string
if "/" not in title_string:
print(title_string)
---
#打印结果
疯狂动物城
---我们注意到,这里只打印了前 25 个结果,如果想要打印 250 个结果,那么就要分析网站地址,发现第二页的网站地址是这样的:
1
https://movie.douban.com/top250?start=25&filter=
在后面写上
?start=xx即可。于是可以写一个 for 循环来完成:1
2
3
4
5for start_num in range(0, 250, 25):
print(start_num)
---
#打印结果
0 25 50 …… 225将
request.get()里面的网址字符串格式化。f表示字符串格式化,它可以将大括号 {} 中的变量值替换为实际的值。在这个网址中,{start_num}会被替换为实际的数字,从而实现动态生成网址的功能。再将前面打印前 25 电影名的代码,写进 for 循环体。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17for start_num in range(0, 250, 25):
response = requests.get(f"https://movie.douban.com/top250?start={start_num}", headers=header)
html = response.text
soup = BeautifulSoup(html, "html.parser")
all_titles = soup.findAll("span", attrs={"class": "title"})
for title in all_titles:
title_string = title.string
if "/" not in title_string:
print(title_string)
---
#打印结果
肖申克的救赎
霸王别姬
阿甘正传
泰坦尼克号
这个杀手不太冷
…… (一直到第 250 个)完成!
拓展练习
以上是根据 B 站一位 Up 主的教程,手把手教着写的。现在只是在终端里打印下来了这 250 个名字,如果我想要做个表格,有序号、中文名、原名、年份、评分、时长、简介。于是开始折腾……
加入了电影原名(第 3 列)
1 | import requests |
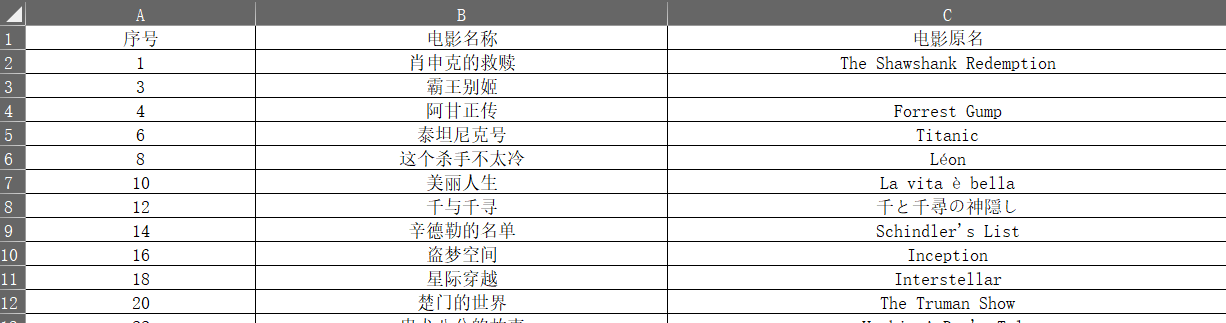
又加入了别名(第 4 列)
1 | import requests |
又加入了年份、国家(第 5、6 列)
1 | import requests |
又加入了简介(第 7 列)
1 | import requests |
但是!它只显示一个国家,而有的作品制片国家不止一个,有两个三个四个的情况,经过一天的努力,通过任务分解法(先去掉一部分,再去掉一部分,再完成替换),于是有了下面的最终完成版!!!
拓展的最终版(注释完全版)
1 | import requests |
算下来花了有两天的功夫,其中昨天(2023/03/09)上午跟着 Up 主学,下午开始写拓展,到了晚上的时候完成。结果快下班的时候发现了国家和地区那里出了问题,一开始想一行代码就完成正则匹配,奈何一直无解,困扰了今天(2023/03/10)一整个上午。下午去车管所回来四点,更新了思路,一步一步实现。又遇到了大闹天宫、茶馆年份和别的条目不太一样的问题,让师弟看了一下,加了 if 判断,搞定!然后又遇到了哈利波特与阿兹卡班的囚徒那里报错,原来是它的 quote 里面有导演这个词,引用就进入了国家的条目,匹配不到,就报错,换了 \n 解决了问题!断点调试流程如下图。(刚刚想起来:年份那里有个 if 判断,而我在国家那里没有加,所以才报错!换成下面的代码就不报错了,即使用导演也没有关系。哎呀,被自己蠢到。)

1 | #输出国家 |

完结撒花✿✿ヽ(°▽°)ノ✿✿